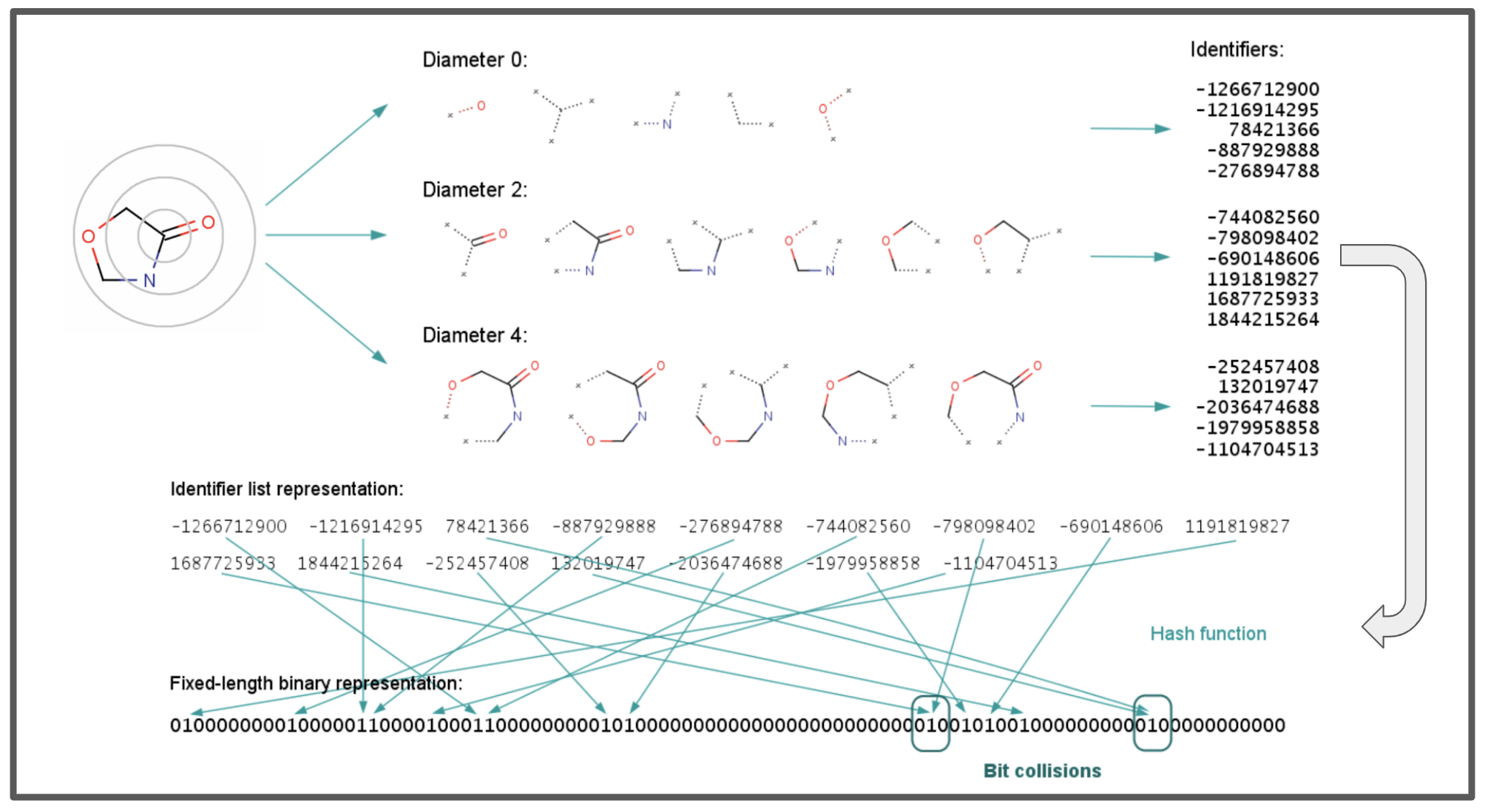
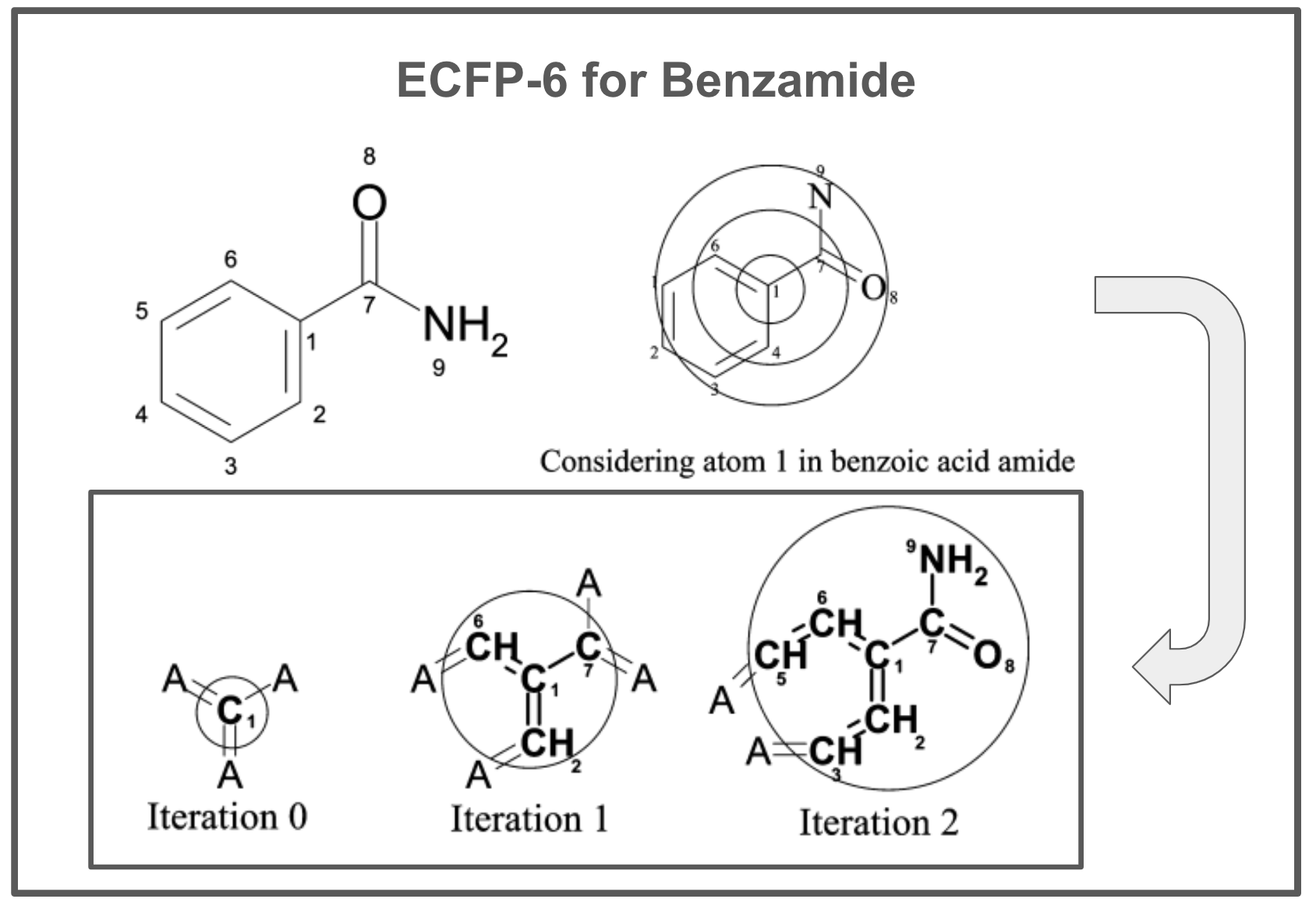
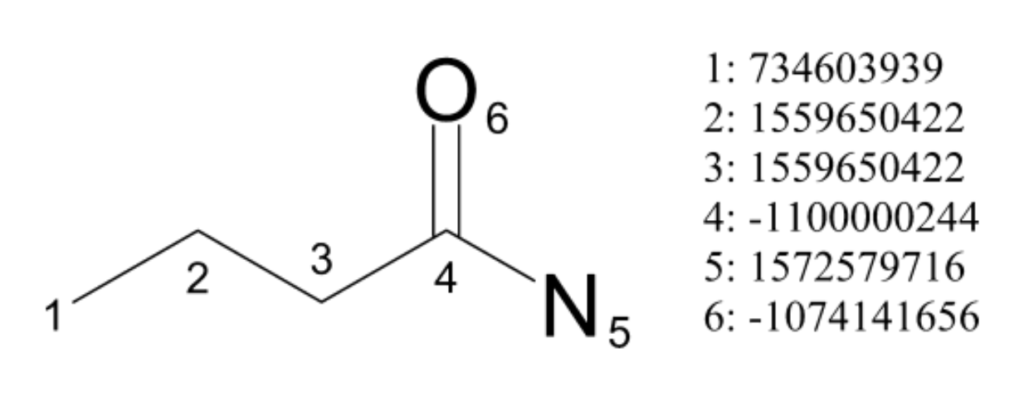
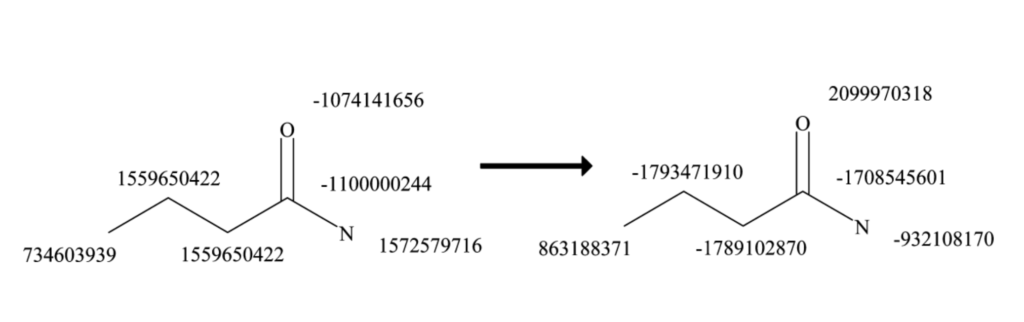
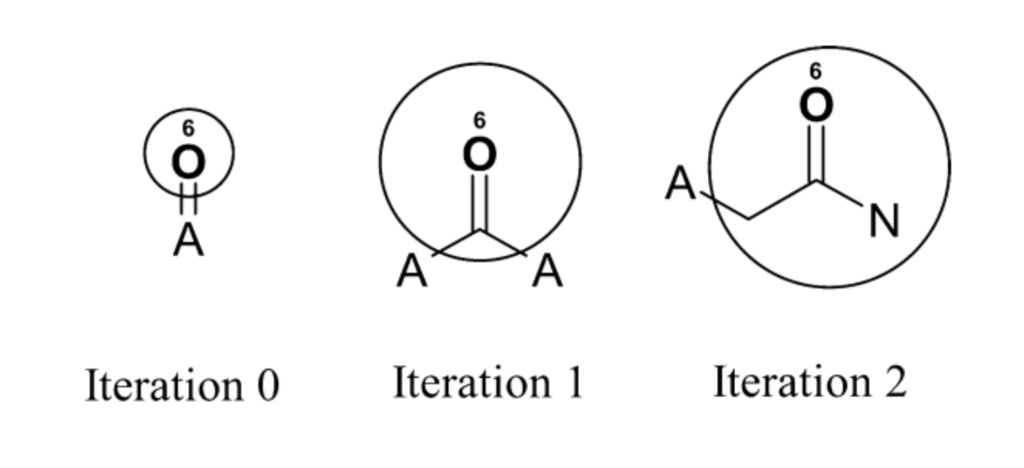
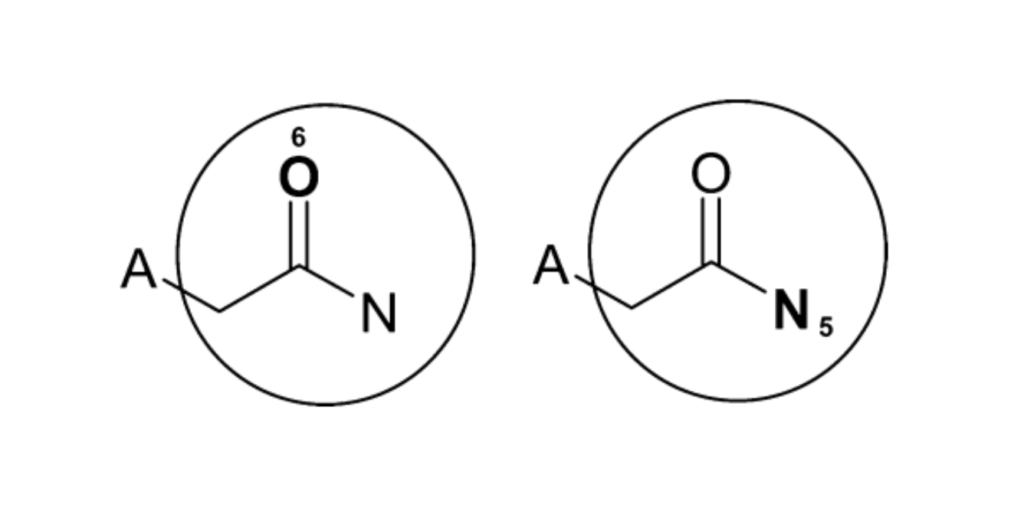
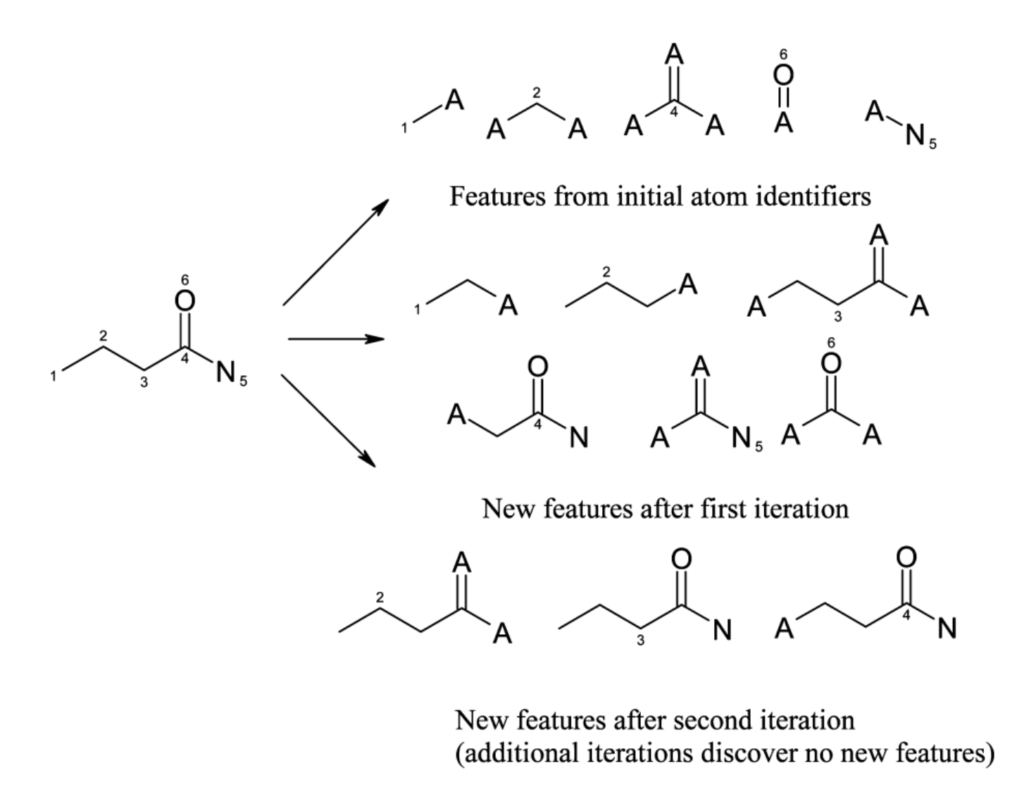
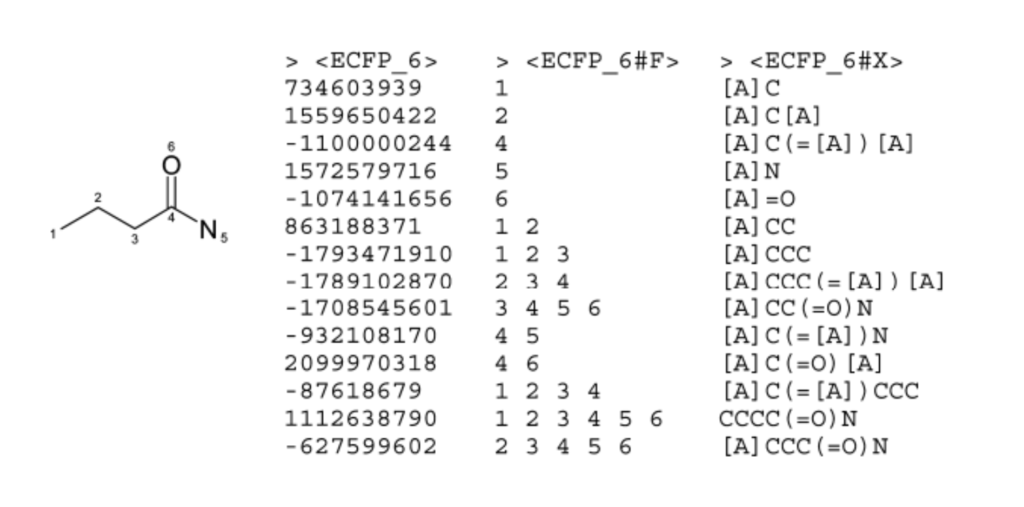
# Imports
from rdkit import Chem
import hashlib
from bitarray import bitarray
# Helper function to flatten a list of tuples
def flatten(lst):
return [item for sublist in lst for item in sublist]
def atom_invariant(atom):
"""
Generates a hash of atom invariants, capturing detailed properties of each atom.
These properties help in uniquely identifying atoms based on their chemical environment.
The hash of these properties serves as a compact identifier for the atom.
(Note: does not include all properties covered in ECFP)
Parameters:
- atom: An RDKit Atom object.
Returns:
- A hash of a tuple containing atom properties including atomic number, total degree (bonds count including hydrogens),
total number of hydrogens, explicit valence, atomic mass, formal charge, and ring membership.
"""
properties = (
atom.GetAtomicNum(), # Atomic number, identifies the element type.
atom.GetNumImplicitHs() + atom.GetNumExplicitHs(), # Number of attached hydrogens (both implicit and explicit)
atom.GetExplicitValence(), # Explicit valence
atom.GetMass(), # Atomic mass
atom.GetFormalCharge(), # Atom's formal charge.
atom.IsInRing() # Boolean indicating if the atom is part of a ring structure.
)
# Return the hash of the properties tuple
return hash(properties)
def get_neighborhood_hash(mol, atom_idx, iteration, previous_neighborhoods, hash_to_bonds):
"""
Calculates a hash for the neighborhood of an atom at a given iteration depth,
and tracks the bonds involved in that neighborhood. The hash and bond tracking
are used to generate extended connectivity fingerprints (ECFPs).
This function iterates over the neighbors of the specified atom, collects
their properties and bond orders, and creates a hash representing the
neighborhood's substructure at the current iteration. Additionally, it
accumulates and updates the set of bonds involved for each unique neighborhood
hash seen across iterations, supporting substructure tracking within the molecule.
Parameters:
- mol (RDKit Mol): The molecule being analyzed.
- atom_idx (int): Index of the atom whose neighborhood hash is being calculated.
- iteration (int): The current iteration depth, controlling the "radius" of
the neighborhood being considered.
- previous_neighborhoods (set): A set of previously encountered neighborhood
hashes to avoid duplications.
- hash_to_bonds (dict): A dictionary mapping unique neighborhood hashes to sets
of bonds (as frozensets of atom indices and bond types) included in each
neighborhood.
Returns:
- (tuple or None, set): A tuple containing the new neighborhood hash (or None
if the neighborhood hash is not new) and the updated set of bonds for the
current neighborhood. If the neighborhood hash is not new, it returns None
instead of the hash to indicate that this particular neighborhood structure
has been previously encountered.
"""
### STEP 1 - GET NEIGHBORHOOD HASH ###
atom = mol.GetAtomWithIdx(atom_idx)
# Start with a list containing the iteration number and the core atom's hash
neighborhood = [(iteration, atom_invariant(atom))]
bond_order_neighbor_pairs = []
# Loop through neighbors and collect each neighbors bond order and hash
for nbr in atom.GetNeighbors():
bond = mol.GetBondBetweenAtoms(atom_idx, nbr.GetIdx())
bond_order = bond.GetBondTypeAsDouble()
neighbor_hash = atom_invariant(nbr)
bond_order_neighbor_pairs.append((bond_order, neighbor_hash))
# Sort the neighbor pairs by bond order, then by neighbor hash
bond_order_neighbor_pairs.sort()
# Extend the neighborhood list with the sorted neighbor information
for pair in bond_order_neighbor_pairs:
neighborhood.append(pair)
# Flatten the list and convert to a tuple for hashing
neighborhood_tuple = tuple(flatten(neighborhood))
neighborhood_hash = hash(neighborhood_tuple)
# Check if the neighborhood hash is new before adding it to previous_neighborhoods
is_new_hash = neighborhood_hash not in previous_neighborhoods
### STEP 2 - BOND TRACKING ###
# Initialize an empty set to accumulate bonds for the current neighborhood hash.
accumulated_bonds = set()
# Accumulate all bonds associated with the core atom and its neighbors from the previous iteration
if iteration > 0:
for prev_hash, prev_bonds in hash_to_bonds.items():
if any(atom_idx in bond_atoms for bond_atoms, bond_type, iter_num in prev_bonds if iter_num == iteration - 1):
accumulated_bonds.update({(bond_atoms, bond_type, iter_num) for bond_atoms, bond_type, iter_num in prev_bonds if iter_num == iteration - 1})
# Collect bonds for tracking, using frozenset for non-directionality (in the context of molecular graphs, a bond between
# atom 0 and atom 1 is the same as a bond between atom 1 and atom 0)
# Each element of the bonds set is a tuple where the first element is a frozenset identifying the bond by the indices of the atoms
# involved, and the second element is the bond type represented as a double. This allows tracking both the connectivity
# and the type of each bond.
for nbr in atom.GetNeighbors():
bond = mol.GetBondBetweenAtoms(atom_idx, nbr.GetIdx())
accumulated_bonds.add((frozenset({atom_idx, nbr.GetIdx()}), bond.GetBondTypeAsDouble(), iteration))
### STEP 3 - UPDATE AND RETURN ###
# Updating ID set and initial collection of bonds for this neighborhood, if it's a new hash
# Decide on what to return based on whether the neighborhood_hash is new
if is_new_hash:
# Add hash to the unique set of IDs passed in during the ecfp call
previous_neighborhoods.add(neighborhood_hash)
hash_to_bonds[neighborhood_hash] = accumulated_bonds
return neighborhood_hash, accumulated_bonds
else:
# Update the existing entry with newly accumulated bonds
hash_to_bonds[neighborhood_hash].update(accumulated_bonds)
return None, accumulated_bonds
def ecfp(mol, radius=2):
"""
Computes the Extended Connectivity Fingerprint (ECFP) for a given molecule, starting with iteration 0
for just the atom identifiers, then expanding in further iterations. Additionally, collects all unique
identifiers generated throughout the iterations.
Parameters:
- mol: An RDKit Molecule object.
- radius: The radius of neighborhoods to consider, corresponding to the iteration count.
Returns:
- A bitarray representing the ECFP of the molecule.
- A list of all unique identifiers generated through all iterations.
- A set of "tracked bonds and substructures"
"""
fp_length = 2048 # Length of the fingerprint bitarray.
fingerprint = bitarray(fp_length)
fingerprint.setall(0)
all_unique_identifiers = set() # Set to keep track of all unique identifiers generated
hash_to_bonds = {} # Dictionary to map unique hashes to their bonds
for iteration in range(0, radius + 1):
for atom_idx in range(mol.GetNumAtoms()):
if iteration == 0:
# Directly use atom_invariant as the unique identifier without neighbor info
atom_hash = atom_invariant(mol.GetAtomWithIdx(atom_idx))
# Add to the set of unique identifiers
all_unique_identifiers.add(atom_hash)
# Map the atom's hash to a position in the fingerprint and set the bit
bit_pos = int(hashlib.sha256(str(atom_hash).encode('utf-8')).hexdigest(), 16) % fp_length
fingerprint[bit_pos] = 1
else:
# Include neighbor information in subsequent iterations
neighborhood_hash, bonds = get_neighborhood_hash(mol, atom_idx, iteration, all_unique_identifiers, hash_to_bonds)
# print(neighborhood_hash)
if neighborhood_hash is not None:
# Add to the set of unique identifiers
all_unique_identifiers.add(neighborhood_hash)
# Store the bonds for this unique hash
hash_to_bonds[neighborhood_hash] = bonds
# Map the hash to a position in the fingerprint and set the bit
bit_pos = int(hashlib.sha256(str(neighborhood_hash).encode('utf-8')).hexdigest(), 16) % fp_length
fingerprint[bit_pos] = 1
# Convert the set of all unique identifiers to a list
unique_identifiers_list = list(all_unique_identifiers)
return fingerprint, unique_identifiers_list, hash_to_bonds